ebonyrack 0.5.2 のリリースとともに、日本語マニュアルを追加しました。
(リリース)
https://github.com/shigenobu/ebonyrack/releases
(マニュアル)
https://github.com/shigenobu/ebonyrack/blob/master/manual/manual.ja.md
これでかなりわかりやすくなったと思うので、
利用者が増えてくれると嬉しいと思っていたりする自分がいます。。
0.5.2 では大掛かりな変更はないのですが、
HTML出力で、これまで<map><area>タグで制御していた部分を、
<svg><rect>タグで制御するように変更しました。
なぜ、svgを採用したかというと、mapだとクリックした場所を目立たせるというようなことが難しく、
そこでsvgとすることでクリックした場所を目立たせるようにすることが可能となりました。
(mapのときの実装)
<img usemap="#components" id="image" src="data:image/png;base64,..."/>
<map name="components">
<area id="a" shape="rect" coords="10,10,20,20"/>
<area id="b" shape="rect" coords="20,20,30,30"/>
<area id="c" shape="rect" coords="30,30,40,40"/>
</map>
<script type="text/javascript">
var es = document.querySelectorAll("area");
for (let i = 0; i < es.length; i++) {
es[i].addEventListener('click', (e) => {
// ダイアログを表示する処理
});
}
</script>
(svgでの実装)
<svg xmlns="http://www.w3.org/2000/svg" width="100" height="100">
<image href="data:image/png;base64,..." width="100" height="100"/>
<rect id="a" x="10" y="10" width="10" height="10" fill="red" fill-opacity="0" stroke="red" stroke-opacity="0"/>
<rect id="b" x="20" y="20" width="10" height="10" fill="red" fill-opacity="0" stroke="red" stroke-opacity="0"/>
<rect id="c" x="30" y="30" width="10" height="10" fill="red" fill-opacity="0" stroke="red" stroke-opacity="0"/>
</svg>
<script type="text/javascript">
var es = document.querySelectorAll("rect");
for (let i = 0; i < es.length; i++) {
es[i].addEventListener('click', (e) => {
// opacityの操作(他のrectのopacityを戻す操作は割愛)
es[i].setAttribute("fill-opacity", "0.2");
es[i].setAttribute("stroke-opacity", "1");
// ダイアログを表示する処理
});
}
</script>
見ていただければわかるかと思うのですが、
svgでrectを作っておき、不可視状態(opacityを0)にしておき、
クリックイベントで可視状態(opacityを0以外)にするというものです。
mapだと、areaのどこをクリックしたのかわかりずらかったものが、
svgとrectを使うことでクリックした場所(対応するオブジェクト)をわかりやすく表示できるようになります。
イメージを添付しておきます。
(初期状態)
(クリック後)※ダイアログが立ち上がっていますが、赤くなっていることがわかるかと。
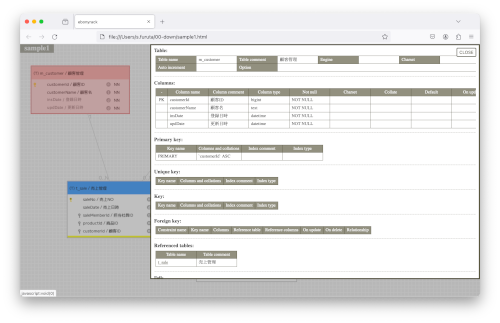
意外とこういうことをコードレベルでやっている人は少ないようで、
svgの仕様見ながら試行錯誤で書いてみました。
今後は、積極的にsvgを活用するのもありだなと思っています。
以上