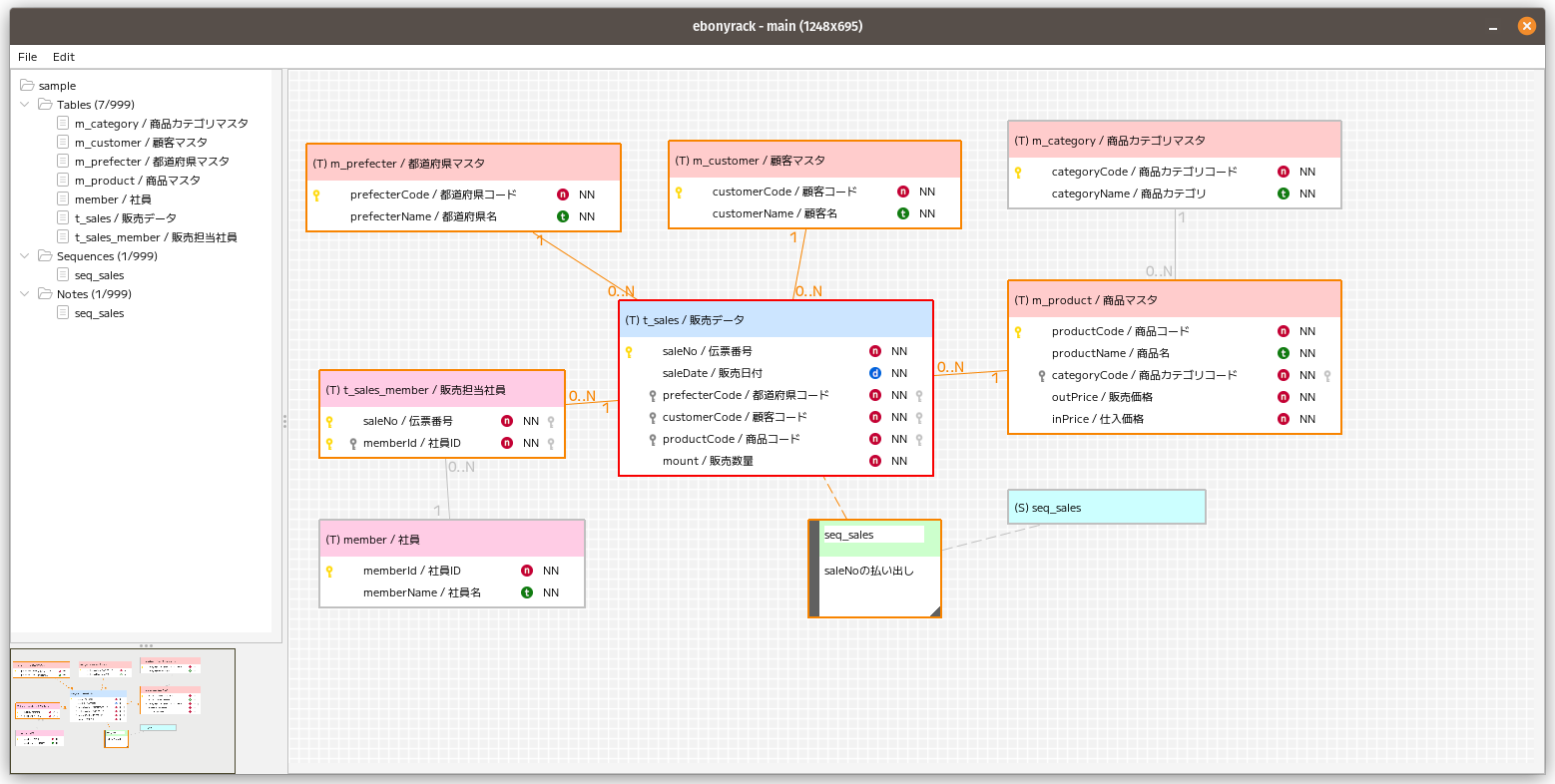
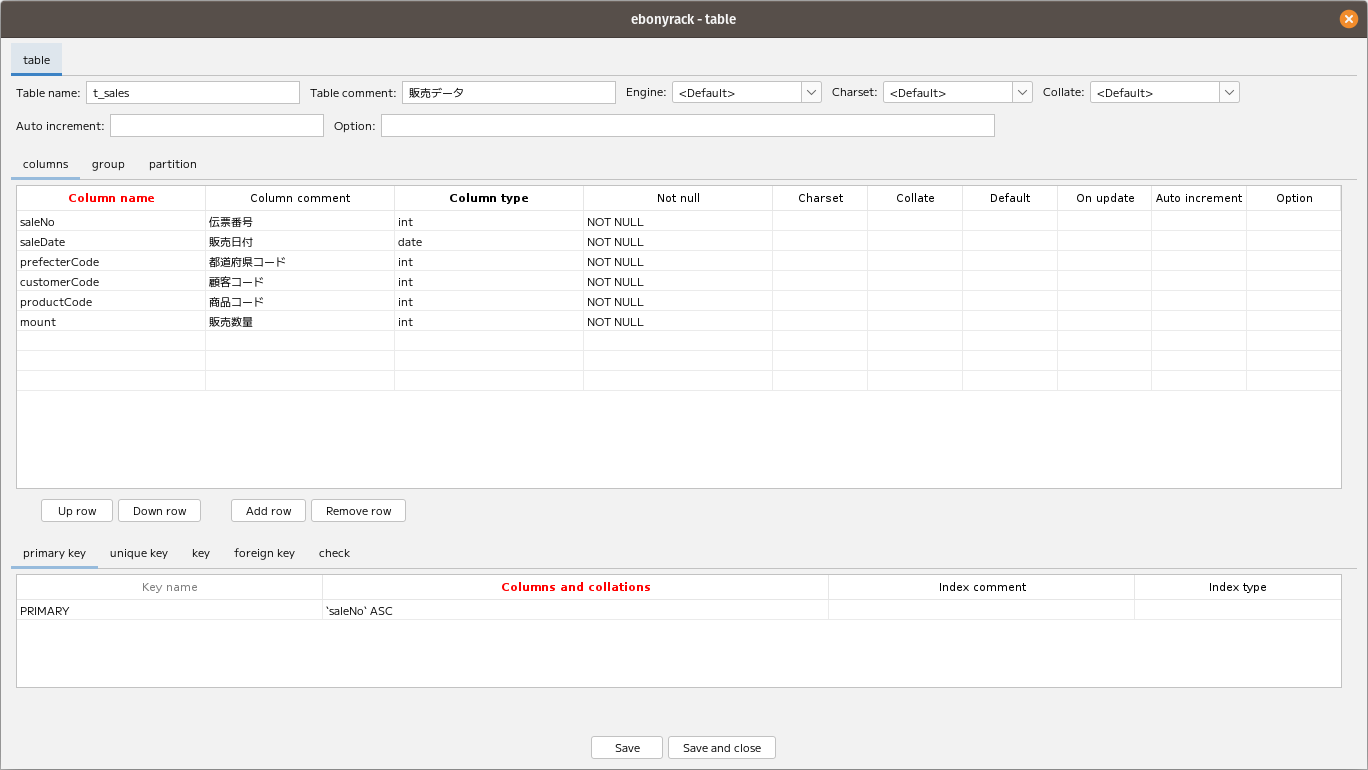
MySQLあたりをよくさわっていたエンジニアにとって、
GCPのSpannerは非常に難しい。
難しいというより、MySQLの感覚でやると上手く行かないのです。
構文は割と似ていて、「`」なんかも使えるから、なおのこと油断しがちです。
銀の弾丸はないよね、という自戒を込めて、注意すべき点について書いておきます。
なお、「速くない」と表現していますが、同一ネットワーク内のMySQLのOLTPの場合と比較してとなります。
条件が変われば、MySQLもそこまでの速度はでないこともありますし、
分散の仕組みが入っていると事情は変わってくるので、その点は予めご了承ください。
●1回のクエリーのRTT(ラウンドトリップタイム)は速くない
MySQLだと、INDEXが聞いていれば(特に主キー)だと、同一ローカルネットワーク内であれば、
0.01秒もかからずデータが取得できますが、
Spannerだと0.01秒くらい平気でかかってしまいます。
そのため、アプリケーションが非同期IOをサポートしているなら、
非同期IOを使ったほうがアプリケーションのパフォーマンスは上がると思います。
とはいえ、1回のトランザクションで、クエリーの本数が多いとキツイので、
仕様でクエリー数を減らせるよう調整できればそれに越したことはないかと思います。
●Queryじゃない、Prepared Statementが大事
MySQLだと、アプリケーションでサーバサイドPrepared Statementをサポートしているライブラリって少ないはず。
「prepare」とか「bind」とかのメソッドがあっても、実はサーバに送るときはQueryになってたりします。
(いわゆるクライアントサイドPrepared Statementというやつですね)
でもMySQLだと、Queryでも全然問題ないほど、構文解析が速いので、
構文解析キャッシュの恩恵を受けられるPrepared Statementを使う必要性は低いのです。
※Prepared Statementを使うと、バイナリプロトコルになるという話もありますが、ここでは割愛。
しかし、Spannerでは、構文解析の負荷は高く、
Prepared Statementを使って、構文解析キャシュの恩恵を受けに行かないと、パフォーマンスがでません。
これは以下にも書いてあるとおりです。
https://cloud.google.com/spanner/docs/sql-best-practices?hl=ja
Queryだと、本当にびっくりするぐらいパフォーマンスでないです。
●1回のSELECTで効果的にデータを取得する
「INTERLEAVE」と「ARRAY STRUCT」が重要です。
「INTERLEAVE」で親と子のテーブルをできるだけ同じノードに閉じ込め、
「ARRAY STRUCT」でまとめてとってくるのがポイントです。
以下に書いてあるとおりです。
https://medium.com/google-cloud-jp/cloud-spanner-%E3%81%A7%E3%82%A4%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%AA%E3%83%BC%E3%83%96%E3%83%86%E3%83%BC%E3%83%96%E3%83%AB%E3%82%92%E9%AB%98%E9%80%9F%E3%81%AB%E5%8F%96%E5%BE%97%E3%81%99%E3%82%8B-2a955b061d3
とはいえ、ARRAY STRUCTでとってきたデータを、オブジェクトにマッピングするのは結構難しいです。
GO言語なんかはライブラリレベルでサポートされているようですが、
他の言語では、自前で解析する必要があります。
上記3つが大きなポイントとなるかと思います。
それ以外にも注意すべきは、「Writeが速くない」ということでしょうか。
UPDATEやDELETEはある意味仕方ないですが、
BULK INSERTについては、UNNESTを上手く使うことで、パフォーマンス向上は可能かと思います。
UNNESTはWHERE INの文脈で使われることが多いかと思いますが、INSERTでも利用できるようです。
※すいません、自分がこれは試してないです。
PostgreSQLでサポートされているので、対応されているのでしょうか。。
他には最近リリースされたINSERT OR UPDATE構文なんかも使えるかもしれません。
ただし、INSERT OR UPDATEについては、ユニークキーがある場合の挙動について、
↓のドキュメントには記載されていません。
https://cloud.google.com/spanner/docs/reference/standard-sql/dml-syntax#insert-or-update
なので、ちょっと試してみました。
まず、こんなテーブルを作ります。
CREATE TABLE UsersUnique
( Id STRING(255) NOT NULL,
Name STRING(255) NOT NULL,
Age INT64 NOT NULL,
)
PRIMARY KEY (Id);
CREATE UNIQUE INDEX uk_UsersUnique_Name ON UsersUnique(Name);
以下のようなデータを入れておきます。
Id Name Age
0123456789 Aさん 20
9876543210 Bさん 40
次に、以下のようなINSERTを流します。
insert or update UsersUnique (Id, Name, Age) values ('0123456789', 'Bさん', 30);
流した結果、
Unique index violation on index uk_UsersUnique_Name at index key [B343201225343202223,9876543210]. It conflicts with row [9876543210] in table UsersUnique.
となりました。
つまり、主キーで置き換えようとしたが、ユニーク制約で引っ掛かった形となりました。
MySQLでは「replace into」といういわゆるUPSERTがあるのですが、
これを使うと、ユニーク制約で削除され、主キーが置き換えられます。
つまり、以下のような結果になります。
Id Name Age
0123456789 Bさん 30
DBMSによって、挙動は違いますが、ユニーク制約がある場合はUPSERTには注意を払いましょう。
あれこれ書いてきましたが、
Spannerは簡単にスケールアウト・スケールインできるのは、本当にすごいなと思いました。
とはいえ、やはり特性をよく知って使わないといけないなということは痛感しています。
(謝辞)
本件のSpanner検証にあたっては、ArmadaSuit さんに尽力いただきました。
ありがとうございました。
彼が作った、cgoによるMySQL/PostgreSQLのUDFは、非常に素晴らしいので、紹介させていただきます。
https://github.com/ArmadaSuit/udf-go
これは、新しいバージョンでのGO言語での書き方で、以前私が作っていたようなUDFより、
洗練されたものとなっています。
以上