awsのELBを使うと、
websocketの場合、
handshakeから60秒がタイムアウトだと思っていた。
しかし、最後の通信(おそらく受信も含む)から60秒がタイムアウトであった。
60秒無通信っていうのは受信も考えるとあまりないかなと。。
また、ELBのタイムアウトも延長できるみたいだから、
websocketを通す場合は、タイムアウトを延長するのも
一つの手段にはなるかなと。
IT系のめもを蓄積していこうかと
awsのELBを使うと、
websocketの場合、
handshakeから60秒がタイムアウトだと思っていた。
しかし、最後の通信(おそらく受信も含む)から60秒がタイムアウトであった。
60秒無通信っていうのは受信も考えるとあまりないかなと。。
また、ELBのタイムアウトも延長できるみたいだから、
websocketを通す場合は、タイムアウトを延長するのも
一つの手段にはなるかなと。
まだwebsocketのネタが完成しないので、
小ネタを。
windowsでjmeterをGUIで起動するとき、
jmeter.bat
なるものをたたく。
ただ、こいつをたたくと、
一緒にcommandプロンプトのコンソールがあがるので、
若干わずらわしい。
そのため、
jmeter.batをちょっと修正。
%JM_START% %JM_LAUNCH% %ARGS% %JVM_ARGS% -jar “%JMETER_BIN%ApacheJMeter.jar” %JMETER_CMD_LINE_ARGS%
↓
start javaw %ARGS% %JVM_ARGS% -jar “%JMETER_BIN%ApacheJMeter.jar” %JMETER_CMD_LINE_ARGS%
これで、batを起動してもコンソールがでなくなる。
さらに、
というソフトを使えば、batをexeファイルに変換してくれるから、
スタートにピン止めできる。
以上
ずいぶん間が空いたけど、
javaでwebsocketやるときのサーバ側クラス設計ができました。
↓のような感じです。
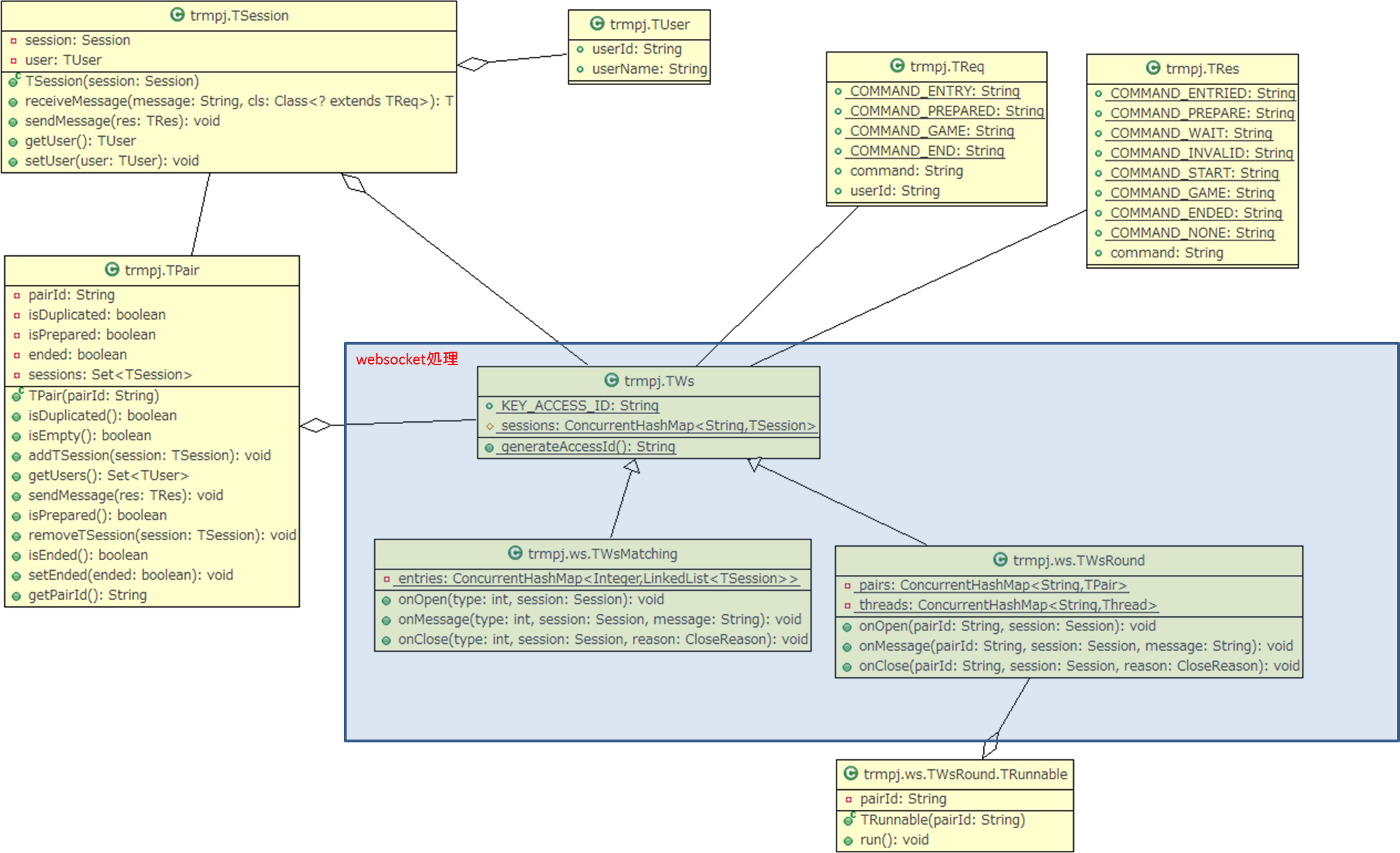
(クラス図あってるかな??)
ポイントとしては、
という感じになります。
スレッドセーフなCollectionでないと、インスタンスの取り違えが起きますので、ご注意を。
ThreadLocalを使うという手もありますが、
websocketの場合、
なので、open時に必要なインスタンスを作成して、closeで破棄するとよいです。
(※messageで作成するときもありますが)
実は、websocketではこの考えは結構重要で、
たとえば、DB接続する際、
messageハンドラで、
connect -> disconnect
を繰り返すと、高負荷に耐えられないです。
ここで、
openハンドラでconnectし、closeハンドラでdisconnectする。
そして、messageハンドラで操作する、
という形だと接続のコストが抑えられるので、
結構有効です。
(※もちろん、アプリケーションの特性によりますが)
次は、javaのソースコードを公開する予定。
node.js側は気力があったら作成します。。
javaからのmail送信ですが、
いろいろ情報が混在しております。
ただ、現時点で、
pom.xmlに以下を記載すれば、
javaSEでも動きます。
<dependency> <groupId>javax.mail</groupId> <artifactId>mail</artifactId> <version>1.5.0-b01</version> </dependency>
以上
前回、awsにtd-agentを入れて、
s3→redshiftとの連携を図ったけど、
さらにうまくやる方法を記載しておく。
●カラムを超えた場合のデータについて
TRUNCATECOLUMNS
オプションを付けておくことで回避できる
●redshiftに取り込まれた日時を登録する方法
テーブル側にカラムを追加して、jsonpathとのカラムミスマッチを防ぐ
具体的には、
CREATE TABLE test_access_logs (
date datetime sortkey,
ip varchar(64),
header varchar(256),
code varchar(16),
size varchar(16),
aaa varchar(64),
bbb varchar(128),
ccc varchar(128),
second varchar(16),
insert_date datetime not null default convert_timezone('JST', getdate())
);
上記みたいに、insert_dateを追加する。
ただし、このまま取り込むと、
{
"jsonpaths": [
"$['date']",
"$['ip']",
"$['header']",
"$['code']",
"$['size']",
"$['aaa']",
"$['bbb']",
"$['ccc']",
"$['second']"
]
}
カラムのミスマッチがおきてしまう。
これを回避するために、
# COPY test_access_logs (date, ip, header, code, size, aaa, bbb, ccc, second) FROM 's3://MY-BUCKET/logs/httpd/201501/26/' credentials 'aws_access_key_id=XXX;aws_secret_access_key=YYY' JSON AS 's3://MY-BUCKET/logs/httpd/test_access_log_jsonpath.json' GZIP COMPUPDATE ON RUNCATECOLUMNS;
上記のように、カラム指定で取り込むと、
insert_dateはnullになり、defaultが適用される。
なぜこのような方法をとるかというと、
もし再取り込みが発生した場合に、
以前のデータを消さないで取り込むと、
重複で取り込まれてしまう。
重複を回避するには、
以前取り込んだデータを削除しなければならない。
insert_dateを登録しておけば、
以前登録したデータを検索できる。
ちなみに、redshift上で、日本時間を取得するには、
# select convert_timezone(‘JST’, getdate());
# select dateadd(hour, 9, getdate());
のような方法がある。
以上
awsにtd-agentを導入して、
httpのアクセスログと、phpの任意のログを、
td-agent -> s3 -> redshift
の流れで投入してみた。
awsのEC2ではtd-agentのバージョン2の導入が大変なので、
バージョン1を導入してみた。
インストールは公式ドキュメントにある通り、以下です。
$ curl -L http://toolbelt.treasuredata.com/sh/install-redhat.sh | sh
※v2はcentos7での動作は確認しましたが、awsではv1を利用
いろいろ情報が混在していたのですが、
S3プラグインは最初から入っていて、
フォーマットはjsonでS3に送信することが可能です。
こんな感じ。
/etc/td-agent/td-agent.conf
<source>
type tail
path /var/www/test/logs/access.log
tag apache.test.access
pos_file /var/log/td-agent/test.access.log.pos
format /^\[(?<date>.*?)\]\[(?<ip>.*?)\]\[(?<header>.*?)\]\[(?<code>.*?)\]\[(?<size>.*?)\]\[(?<aaa>.*?)\]\[(?<bbb>.*?)\]\[(?<ccc>.*?)\]\[(?<second>.*?)\]$/
</source>
<match apache.test.access>
type s3
aws_key_id XXX
aws_sec_key YYY
s3_bucket MYBUCKET
s3_endpoint s3-ap-northeast-1.amazonaws.com
path logs/httpd/
buffer_path /var/log/td-agent/httpd/test-access.log
time_slice_format %Y%m/%d/test-acccess.log.%Y%m%d%H%M
retry_wait 30s
retry_limit 5
flush_interval 1m
flush_at_shutdown true
format json
</match>
※httpdアクセスログのフォーマットは、
LogFormat “[%{%Y-%m-%d %H:%M:%S %Z}t][%h][%r][%>s][%b][%{X-AAA}i][%{X-BBB}i][%{X-CCC}i][%T]” hoge
です。
でもって、S3には
test-acccess.log.201501270938_0.gz
こんな感じのログが保存されている。
中身は、
{“date”:”2015-01-27 09:38:10 JST”,”ip”:”182.118.55.177″,”header”:”GET / HTTP/1.1″,”code”:”200″,”size”:”11″,”aaa”:”-“,”bbb”:”-“,”ccc”:”-“,”second”:”0″}
みたいな感じ。
んでもって、
s3上にlogs/httpd/test_access_log_jsonpath.jsonってファイルを作成しておく
{
"jsonpaths": [
"$['date']",
"$['ip']",
"$['header']",
"$['code']",
"$['size']",
"$['aaa']",
"$['bbb']",
"$['ccc']",
"$['second']"
]
}
そして、テーブルを作成しておく。
CREATE TABLE test_access_logs (
date datetime sortkey,
ip varchar(64),
header varchar(256),
code varchar(16),
size varchar(16),
aaa varchar(64),
bbb varchar(128),
ccc varchar(128),
second varchar(16)
);
この状態でredshift上から、
# COPY test_access_logs FROM 's3://MY-BUCKET/logs/httpd/201501/26/' credentials 'aws_access_key_id=XXX;aws_secret_access_key=YYY' JSON AS 's3://MY-BUCKET/logs/httpd/test_access_log_jsonpath.json' GZIP COMPUPDATE ON;
ってやれば、あらかじめ作成しておいたテーブルにデータが突っ込まれる。
上記のcreateでは、圧縮オプションはつけていないが、
繰り返しが多い項目に圧縮オプションつけておくと、
かなり削減になる。
【参考】
1000万件のデータを突っ込んだ際、元容量の70%くらいになった。
(あくまで一例ね。)
だた、アクセスログなんかは、比較的繰り返しが多い項目もあるので、
その辺は効果的にやるとよいかもね。
websocketにおいて、
node.jsでpm2を使う際の問題点をまとめてみる。
バージョンは、
<node.js>
v0.10.xx
<pm2>
v0.11.xx
v0.12.xx
上記の場合、pm2のバージョンに関わらず、
という感じです。
clusterモードの最悪な点として、
1.アプリが落ちる⇒2.再起動⇒3.ポート開放されずにアクセス不可能
となる点かなと。
これが4プロセス起動していたら、
1プロセスのダウンが全プロセスに影響すること。
つまり、
pm2 start app.js -i 4
なんてして、4プロセス起動しても、
1プロセスダウンすれば、もうおしまい。
1つのプロセスの再起動が、他プロセスにも影響して、アクセス不可能になる。
再起動の抑止オプションがあれば、まだいけそうな気もするが。。。
回避するには、
node自体をv.11.xx(現時点でunstable)にすればいけるようだが、未検証なので、何とも言えない。。。
じゃあ、forkモードで起動すればいいじゃんとなりますが、
forkの場合は、プロセスとポートが1対1なので、
4プロセス起動するには、4ポート必要になりますので、柔軟性は低くなる。
ただ、forkモードでは、再起動時にポート開放されますので、
node.jsの前に置くフロントサーバをコントロールできれば問題はないかなと。
まだまだ、node.jsは発展途上なわけなので、
このあたりのリスクを十分に踏まえる必要がありますね。
余談ですが、websocketは再起動が命取りになるので、
foreverでポート分散して、再起度を抑止するようにしておくほうが
現在取りうる手段としてはベターかなと感じています。
nicを2本差しのゲートウェイサーバを構築していたのですが、
久しぶりにlinuxとハードウェアではまったので、
記録しておく。
【パターン1】
・centos6.6 + pcie x1 Marvel 88E8053
nicは大手量販店で購入したもの。
pcieのボードはこれしかなかった。。
→(結果)ドライバーをダウンロードして(ここから)、ビルドするものの、
ドライバーはロードできているが、nic自体を認識せず。
【パターン2】
・centos7.0 + pcie x1 Marvel 88E8053
→(結果)ドライバーのビルド自体失敗。
【パターン3】
・ubuntu14LTS + pcie x1 Marvel 88E8053
→(結果)ドライバーのビルド自体失敗。
どうやら、このドライバーは、
カーネル3系には対応していないようであった。
【パターン4】
・centos7.0 + buffalo LUA3-U2-ATX
→(結果)刺した瞬間うまくいった。
100MBPSだけどね。。
最近はlinuxでもかなりハードを認識するから
行けるかと踏んでいたが、
そんなこともないものでした。
ちなみに、2本刺しと書きましたが、
1本はオンボードで、こいつは問題なしでありました。(broadcom製)
よく忘れるので、
virtualboxのネットワーク設定をメモ。
【目標】
【手順】
起動後、
ホストOSからゲストOSへssh接続で確認。
ゲストOSからpingを発行して、ホスト側(またはインターネット)につながればOK。
以上
firefoxで開発に役立つプラグインを紹介します。
●Firebug
言わずと知れたデバッカー。
chromeよりやりやすいと思うのは自分だけか?
●FireMobileSimulator
携帯のUser-Agent等を設定できるシュミレーター。
今はあんまりつかわないけど。
●Live HTTP headers
たまにつかう。
ページを遷移しても、ヘッダーをキャプチャーしてくれるので、
Firebugをちょっとだけ補える。
●Modify Headers
拡張ヘッダーを送るときに使う。
chromeのDev Http Clientってのより、
ブラウザ感覚で送れてよいかな。
●Pearl Crescent Page Saver Basic
たまに画面キャプチャーをとるときに使う。
スクロール先も含めてキャプチャーしてくれるので、
そこがかなりうれしい。