前回、awsにtd-agentを入れて、
s3→redshiftとの連携を図ったけど、
さらにうまくやる方法を記載しておく。
●カラムを超えた場合のデータについて
TRUNCATECOLUMNS
オプションを付けておくことで回避できる
●redshiftに取り込まれた日時を登録する方法
テーブル側にカラムを追加して、jsonpathとのカラムミスマッチを防ぐ
具体的には、
CREATE TABLE test_access_logs (
date datetime sortkey,
ip varchar(64),
header varchar(256),
code varchar(16),
size varchar(16),
aaa varchar(64),
bbb varchar(128),
ccc varchar(128),
second varchar(16),
insert_date datetime not null default convert_timezone('JST', getdate())
);
|
上記みたいに、insert_dateを追加する。
ただし、このまま取り込むと、
{
"jsonpaths": [
"$['date']",
"$['ip']",
"$['header']",
"$['code']",
"$['size']",
"$['aaa']",
"$['bbb']",
"$['ccc']",
"$['second']"
]
}
|
カラムのミスマッチがおきてしまう。
これを回避するために、
# COPY test_access_logs
(date, ip, header, code, size, aaa, bbb, ccc, second)
FROM 's3://MY-BUCKET/logs/httpd/201501/26/'
credentials 'aws_access_key_id=XXX;aws_secret_access_key=YYY'
JSON AS 's3://MY-BUCKET/logs/httpd/test_access_log_jsonpath.json'
GZIP
COMPUPDATE ON
RUNCATECOLUMNS;
|
上記のように、カラム指定で取り込むと、
insert_dateはnullになり、defaultが適用される。
なぜこのような方法をとるかというと、
もし再取り込みが発生した場合に、
以前のデータを消さないで取り込むと、
重複で取り込まれてしまう。
重複を回避するには、
以前取り込んだデータを削除しなければならない。
insert_dateを登録しておけば、
以前登録したデータを検索できる。
ちなみに、redshift上で、日本時間を取得するには、
# select convert_timezone(‘JST’, getdate());
# select dateadd(hour, 9, getdate());
のような方法がある。
以上
投稿日時:2015年01月29日 11:02
カテゴリー:
aws,
server
awsにtd-agentを導入して、
httpのアクセスログと、phpの任意のログを、
td-agent -> s3 -> redshift
の流れで投入してみた。
awsのEC2ではtd-agentのバージョン2の導入が大変なので、
バージョン1を導入してみた。
インストールは公式ドキュメントにある通り、以下です。
$ curl -L http://toolbelt.treasuredata.com/sh/install-redhat.sh | sh
※v2はcentos7での動作は確認しましたが、awsではv1を利用
いろいろ情報が混在していたのですが、
S3プラグインは最初から入っていて、
フォーマットはjsonでS3に送信することが可能です。
こんな感じ。
/etc/td-agent/td-agent.conf
<source>
type tail
path /var/www/test/logs/access.log
tag apache.test.access
pos_file /var/log/td-agent/test.access.log.pos
format /^\[(?<date>.*?)\]\[(?<ip>.*?)\]\[(?<header>.*?)\]\[(?<code>.*?)\]\[(?<size>.*?)\]\[(?<aaa>.*?)\]\[(?<bbb>.*?)\]\[(?<ccc>.*?)\]\[(?<second>.*?)\]$/
</source>
<match apache.test.access>
type s3
aws_key_id XXX
aws_sec_key YYY
s3_bucket MYBUCKET
s3_endpoint s3-ap-northeast-1.amazonaws.com
path logs/httpd/
buffer_path /var/log/td-agent/httpd/test-access.log
time_slice_format %Y%m/%d/test-acccess.log.%Y%m%d%H%M
retry_wait 30s
retry_limit 5
flush_interval 1m
flush_at_shutdown true
format json
</match>
|
※httpdアクセスログのフォーマットは、
LogFormat “[%{%Y-%m-%d %H:%M:%S %Z}t][%h][%r][%>s][%b][%{X-AAA}i][%{X-BBB}i][%{X-CCC}i][%T]” hoge
です。
でもって、S3には
test-acccess.log.201501270938_0.gz
こんな感じのログが保存されている。
中身は、
{“date”:”2015-01-27 09:38:10 JST”,”ip”:”182.118.55.177″,”header”:”GET / HTTP/1.1″,”code”:”200″,”size”:”11″,”aaa”:”-“,”bbb”:”-“,”ccc”:”-“,”second”:”0″}
みたいな感じ。
んでもって、
s3上にlogs/httpd/test_access_log_jsonpath.jsonってファイルを作成しておく
{
"jsonpaths": [
"$['date']",
"$['ip']",
"$['header']",
"$['code']",
"$['size']",
"$['aaa']",
"$['bbb']",
"$['ccc']",
"$['second']"
]
}
|
そして、テーブルを作成しておく。
CREATE TABLE test_access_logs (
date datetime sortkey,
ip varchar(64),
header varchar(256),
code varchar(16),
size varchar(16),
aaa varchar(64),
bbb varchar(128),
ccc varchar(128),
second varchar(16)
);
|
この状態でredshift上から、
# COPY test_access_logs
FROM 's3://MY-BUCKET/logs/httpd/201501/26/'
credentials 'aws_access_key_id=XXX;aws_secret_access_key=YYY'
JSON AS 's3://MY-BUCKET/logs/httpd/test_access_log_jsonpath.json'
GZIP
COMPUPDATE ON;
|
ってやれば、あらかじめ作成しておいたテーブルにデータが突っ込まれる。
上記のcreateでは、圧縮オプションはつけていないが、
繰り返しが多い項目に圧縮オプションつけておくと、
かなり削減になる。
【参考】
1000万件のデータを突っ込んだ際、元容量の70%くらいになった。
(あくまで一例ね。)
だた、アクセスログなんかは、比較的繰り返しが多い項目もあるので、
その辺は効果的にやるとよいかもね。
投稿日時:2015年01月27日 17:51
カテゴリー:
aws,
server
websocketにおいて、
node.jsでpm2を使う際の問題点をまとめてみる。
バージョンは、
<node.js>
v0.10.xx
<pm2>
v0.11.xx
v0.12.xx
上記の場合、pm2のバージョンに関わらず、
- windowsでは使えない
- clusterモードで再起動(restart)を行うと、ポート開放されない(→killする必要あり)
- GodDaemonを起動したユーザ以外では操作不可能(pm2 listでもGodDaemonが起動するので要注意)
- 再起動の抑制オプションがない
という感じです。
clusterモードの最悪な点として、
1.アプリが落ちる⇒2.再起動⇒3.ポート開放されずにアクセス不可能
となる点かなと。
これが4プロセス起動していたら、
1プロセスのダウンが全プロセスに影響すること。
つまり、
pm2 start app.js -i 4
なんてして、4プロセス起動しても、
1プロセスダウンすれば、もうおしまい。
1つのプロセスの再起動が、他プロセスにも影響して、アクセス不可能になる。
再起動の抑止オプションがあれば、まだいけそうな気もするが。。。
回避するには、
node自体をv.11.xx(現時点でunstable)にすればいけるようだが、未検証なので、何とも言えない。。。
じゃあ、forkモードで起動すればいいじゃんとなりますが、
forkの場合は、プロセスとポートが1対1なので、
4プロセス起動するには、4ポート必要になりますので、柔軟性は低くなる。
ただ、forkモードでは、再起動時にポート開放されますので、
node.jsの前に置くフロントサーバをコントロールできれば問題はないかなと。
まだまだ、node.jsは発展途上なわけなので、
このあたりのリスクを十分に踏まえる必要がありますね。
余談ですが、websocketは再起動が命取りになるので、
foreverでポート分散して、再起度を抑止するようにしておくほうが
現在取りうる手段としてはベターかなと感じています。
投稿日時:2015年01月13日 12:47
カテゴリー:
node.js,
websocket
nicを2本差しのゲートウェイサーバを構築していたのですが、
久しぶりにlinuxとハードウェアではまったので、
記録しておく。
【パターン1】
・centos6.6 + pcie x1 Marvel 88E8053
nicは大手量販店で購入したもの。
pcieのボードはこれしかなかった。。
→(結果)ドライバーをダウンロードして(ここから)、ビルドするものの、
ドライバーはロードできているが、nic自体を認識せず。
【パターン2】
・centos7.0 + pcie x1 Marvel 88E8053
→(結果)ドライバーのビルド自体失敗。
【パターン3】
・ubuntu14LTS + pcie x1 Marvel 88E8053
→(結果)ドライバーのビルド自体失敗。
どうやら、このドライバーは、
カーネル3系には対応していないようであった。
【パターン4】
・centos7.0 + buffalo LUA3-U2-ATX
→(結果)刺した瞬間うまくいった。
100MBPSだけどね。。
最近はlinuxでもかなりハードを認識するから
行けるかと踏んでいたが、
そんなこともないものでした。
ちなみに、2本刺しと書きましたが、
1本はオンボードで、こいつは問題なしでありました。(broadcom製)
投稿日時:2014年12月19日 14:19
カテゴリー:
server
よく忘れるので、
virtualboxのネットワーク設定をメモ。
【目標】
- ホストOSは固定IP(192.168.1.10)
- ゲストOSは固定IP(192.168.1.11)
- ホストOSとゲストOSは同一ネットワーク(255.255.255.0)
- 同一ネットワーク内から、ゲストOSへ接続可能
- ゲストOSは外部へ接続可能(※yumとかできないからね)
【手順】
- virtualboxのインストール
- ホストオンリーアダプターと、wifi(ホストが使っている)をブリッジ
- ブリッジしたアダプターのIPをwifiで使っていたものに変更(192.168.1.10)
- ゲストOSのネットワーク設定で、「ホストオンリーアダプター」を選択
- ゲストOSをインストールし、固定IP(192.168.1.11)を割り当てる
起動後、
ホストOSからゲストOSへssh接続で確認。
ゲストOSからpingを発行して、ホスト側(またはインターネット)につながればOK。
以上
投稿日時:2014年12月11日 15:32
カテゴリー:
virtualbox
firefoxで開発に役立つプラグインを紹介します。
●Firebug
言わずと知れたデバッカー。
chromeよりやりやすいと思うのは自分だけか?
●FireMobileSimulator
携帯のUser-Agent等を設定できるシュミレーター。
今はあんまりつかわないけど。
●Live HTTP headers
たまにつかう。
ページを遷移しても、ヘッダーをキャプチャーしてくれるので、
Firebugをちょっとだけ補える。
●Modify Headers
拡張ヘッダーを送るときに使う。
chromeのDev Http Clientってのより、
ブラウザ感覚で送れてよいかな。
●Pearl Crescent Page Saver Basic
たまに画面キャプチャーをとるときに使う。
スクロール先も含めてキャプチャーしてくれるので、
そこがかなりうれしい。
投稿日時:2014年12月09日 16:03
カテゴリー:
firefox
jdk7からjdk8に変えた時、
Runnableのスコープ外で宣言した変数が、
Runnable内でfinalを付けないで参照できた。
java7だと、
int numberLocal = 1;
Thread t = new Thread(new Runnable() {
final int numberThread = numberLocal;
};
|
java8だと、
int numberLocal = 1;
Thread t = new Thread(new Runnable() {
int numberThread = numberLocal;
};
|
のような感じで、java8だとfinalが不要らしい。
ただし、書き換えるとエラーになるので、
暗黙的なfinalということになるようです。
投稿日時:2014年12月09日 15:36
カテゴリー:
java
前回ゲーム仕様を決めたので、
今回は詳細は処理フローを作成します。
以下のような感じを想定しています。
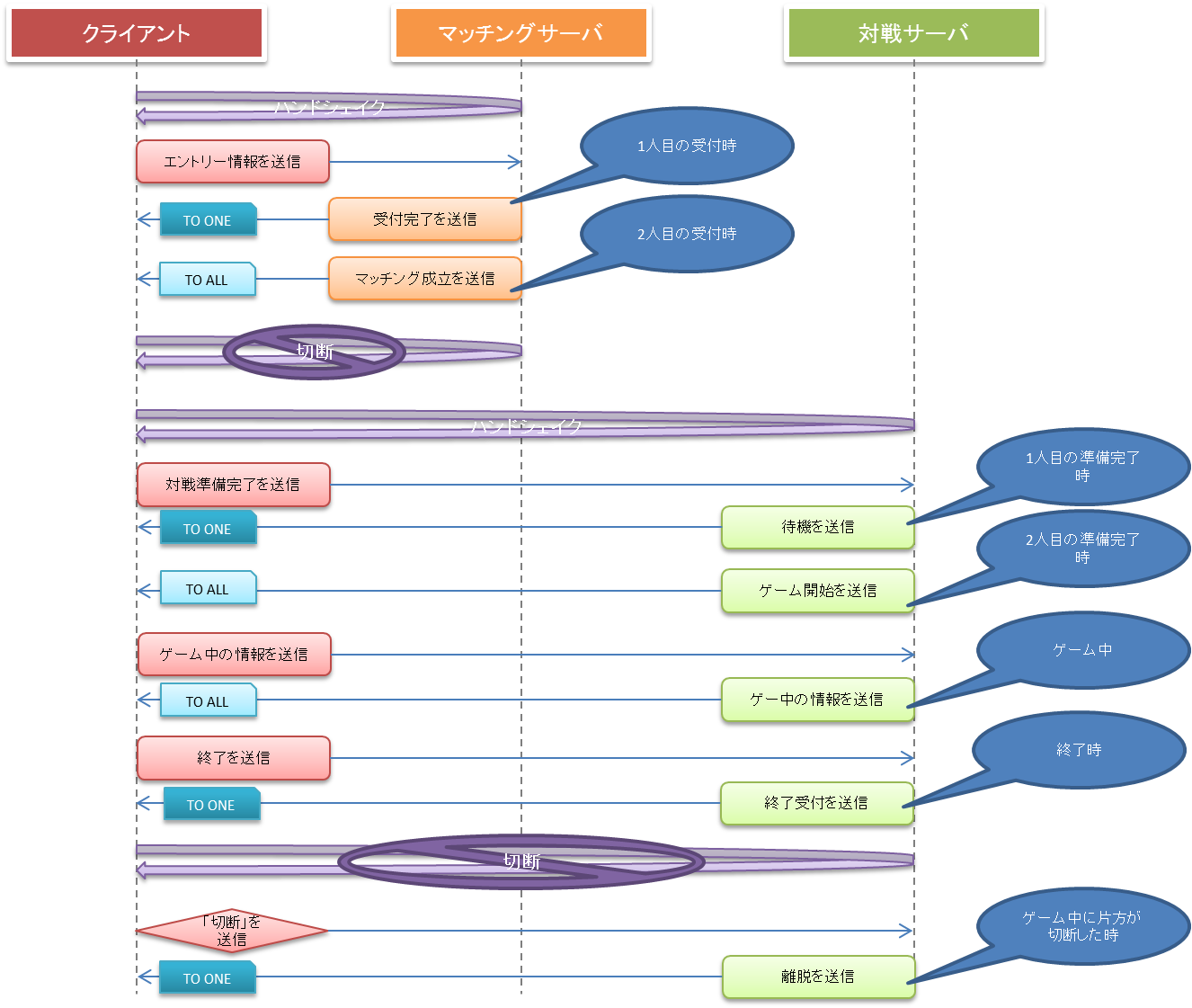
上記イメージの解説です。
- マッチングサーバと接続します。
- エントリーに必要な情報をおくります。サーバ側が1人目の受付の場合、「受付完了」という情報を返します。もし、ここで、2人目なら、「成立完了」という情報を2人に返します。
- 「成立完了」を受け取ったクライアントは、マッチングサーバから抜けて、対戦サーバ側と接続します。
- 対戦サーバと接続したら、「準備完了」を送ります。ここで、2人がそろって初めて「開始」を返します。
- ゲーム中は、片側(相手)から送られた情報を、2人に送信します。
- 無事ゲームが終わったら(終了判断はクライアントに依存)、1人1人が別々に「終了」を送信し、「終了」を受け取ったら各人で、対戦サーバから抜けます。
- もし、ゲームが始まっている状態で、片側(相手)が切断したら、残っている方に「相手が切断した」という情報を送ります。今回の仕様では、相手の勝利となり、相手側は「終了」を送信します。
ポイントは4、6、7です。
4のとき、相手が来ないケースもあるので、制限時間以内に相手が来なかったらどのような情報を返すかをサーバ側で対応する必要があります。
6はなぜ2人に送信しないかというと、下手に2人に送信してしまうと、終了時のクライアントの表示を片側が変更可能となってしまうからです。
7は片方の切断時に、残っている方へ何かしらの通知を行う対応です。
pub/subを使わない前提である以上、
上記の操作をすべてメモリ上の変数にて制御をかけます。
(※当然サービスのレベルでは、何かしらのデータベースへ書き込む等がありますが、ここでは考慮しません。)
次は、サーバ側のクラス設計を書きます。
投稿日時:2014年12月01日 12:43
カテゴリー:
java,
node.js,
websocket
プレビュー版のようですが、
MySQLと互換性をもつRDSが発表されましたね。
詳しくは、こちら。
ちょっと気になるのは、
AmazonのEC2で選択できるAmazonLinuxって、centos6系をベースにカスタマイズされたものだったような。
centosは7から、標準レポジトリにMySQLが外れて、mariadbになってたから、
当面はAmazonLinuxはcentos7には上げないのかね?
EC2とRDSで違うから、問題ないのかもしれないけど、
mariadbもaws(特にRDS)で使えるようになると、今後もっと流行りそうな気がします。
投稿日時:2014年11月26日 13:16
カテゴリー:
aws,
mariadb,
mysql
今のところ、3回にわたりwebsocketの比較を書いてきましたが、
これからは、
となります。
とその前に、一服。
個人的な見解としては、
node.jsよりjavaの方がwebsocketは組みやすいかなと思っています。
理由は、
- 過去資産が豊富なので、選択肢が多い
- 型制約があるので、全体的に堅牢になる
- eclipseなどのIDEが優秀
といったところでしょうか。
node.jsはjavascriptなので、
なんでもできてしまう分(たとえば、ユーザ定義オブジェクトになんでも突っ込めるとか)、
コードがわかりにくくなりがちです。(※規約で気を付けないとね)
また、IOが基本的に非同期で実行されるとかが、
やっぱりやりにくいなと感じてます。
ただ、java側はAPサーバを動かすコスト(メモリ消費)がやや高いので、
省エネなのはnode.jsかなとも思います。
ちなみに、javaでwebsocketをやる場合、
jetty8とかは独自実装になっており、
jetty9でJSR356に対応してます。
※jetty9の場合、jettyの独自パッケージの中で、JSR356に読み替えているようです。mavenのpomファイルも後で作成します。
JSR356に対応しておけば、tomcatに移植しても動くので、独自実装はもう使わないほうがよかです。
なお、あのplayframework2.3のwebsocketはjetty8でした。(playは機能面はすごいけど、ちょっと重いよね。。)
最終的には、どちらもクセはあります。
取り巻く環境、開発者の経験等を考慮して、
選択するとよいと思います。
(go言語なんかでもやっている人はいるのかな?goはこれから勉強します。)
投稿日時:2014年11月26日 13:04
カテゴリー:
java,
node.js,
websocket